스프링 부트 핵심 가이드

1. MySQL 설치
글에서는 마리아 DB를 사용한다고 했지만 필자는 사전에 MySQL을 설치했을뿐만 아니라 MySQL이 Oracle 다음으로 가장 많이 사용되고 있기 때문에 이 글에서도 MySQL을 사용하고자 한다.
맥북의 경우 Homebrew를 설치했었다면 다음 명령어로 쉽게 설치가능하다
brew install mysql // 설치
mysql -V // 버전 확인
설치가 완료되면 설정을한다.
$ mysql_secure_installation
위의 명령어로 root 비밀번호 초기화 및 보안 강화를 진행한다.
Would you like to setup VALIDATE PASSWORD component? => 암호의 강도를 확인 Yes
Remove anonymous users? => 익명의 사용자 Yes
Disallow root login remotely? => 원격접속 가능? No
Remove test database and access to it? => testDB만들어둔 것을 지울 것인가? No
Reload privilege tables now? => 지금 반영할 것인가? Yes
All done! 나오면 끝!
편하게 작업하기 위해 DB툴까지 설치했는데 아래의 블로그를 참고하면 좋을 것 같다.
https://velog.io/@jiyounghi/SpringBoot-mac-mysql-DBeaver-%EC%84%A4%EC%B9%98-%EC%97%B0%EB%8F%99
2. ORM
ORM(Object Relational Mapping) : 객체 관계 매핑, 자바와 같은 객체 지향 언어에서 의미하는 객체와 RDB(Relational Database)의 테이블을 자동으로 매핑하는 방법
객체 지향 언어에서의 객체 = Class
Class는 데이터베이스의 테이블과 매칭하기 위해 만들어진 것이 아니기 때문에 RDB 테이블과 어쩔 수 없이 불일치 존재
ORM은 클래스와 RDB 테이블 간 불일치와 제약사항을 해결

ORM의 장점
- ORM을 사용하면서 데이터베이스 쿼리를 객체지향적으로 조작 가능
- 객체지향적으로 데이터베이스에 접근할 수 있어 코드의 가독성을 높임
- 쿼리문을 작성하는 양이 현저히 줄어들어 개발 비용이 줄어듬
- 재사용 및 유지보수 편리
- ORM을 통해 매핑된 객체는 모두 독립적으로 작성되어 있어 재사용에 용이함
- 객체들은 각 클래스로 나뉘어 있어 유지보수가 쉬움
- 데이터베이스에 대한 종속성이 줄어듬
- ORM을 통해 자동 생성된 SQL문은 객체를 기반으로 데이터베이스 테이블을 관리하기 때문에 데이터베이스에 종속적이지 않음
- 데이터베이스를 교체하는 상황에서도 비교적 적은 리스크를 부담
ORM의 단점
- ORM만으로 온전한 서비스를 구현하기에는 한계 존재
- 복잡한 서비스의 경우 직접 쿼리를 구현하지 않고 코드를 구현하기 어려움
- 복잡한 쿼리를 정확한 설계 없이 ORM만으로 구성하게 되면 속도 저하 등의 성능 문제가 발생 가능
- 애플리케이션의 객체 관점과 데이터베이스의 관계 관점의 불일치가 발생
- 세분성(Granularity): ORM의 자동설계 방법에 따라 데이터베이스에 있는 테이블의 수와 애플리케이션의 엔티티(Entity) 클래스의 수가 다른 경우가 생김 (클래스 수 > 테이블의 수)
- 상속성(Inheritance): RDBMS에는 상속이라는 개념이 없음
- 식별성(Identity): RDBMS는 기본키(primary key)로 동일성을 정의. 하지만 자바는 두 객체의 값이 같아도 다르다고 판단할 수 있음. 식별과 동일성의 문제
- 연관성(Associations): 객체지향 언어는 객체를 참조함으로써 연관성을 나타내지만 RDBMS는 외래키(foreign key)를 삽입함으로써 연관성을 표현. 또한 객체 지향 언어에서 객체를 참조할 때는 방향성이 존재하지만, RDBMS에서 외래키를 삽입하는 것은 양방향의 관계를 가지기 때문에 방향성이 없음
- 탐색(Navigation): 자바와 RDBMS는 어떤 값(객체)에 접근하는 방식이 다름. 자바에서는 특정 값에 접근하기 위해 ㄱㄱ체 참조 같은 연결 수단을 활용. 이 방식은 객체를 연결하고 또 연결해서 접근하는 그래프 형태의 접근 방식.( ex: 특정 멤버의 회사 주소를 구하기 위해 member.getOragniztion().getAddress()와 같이 접근) 반면, RDBMS에서는 쿼리를 최소화 하고 조인(JOIN)을 통해 여러 테이블을 로드하고 값을 추출하는 접근방식을 채택
3. JPA
JPA(Java Persistence API): 자바 진영의 ORM 기술 표준으로 채택된 인터페이스 모음 (ORM > JPA)
즉, JPA 또한 실제로 동작하는 것이 아니라 어떻게 동작해야 하는지 메커니즘을 정리한 표준 명세

내부적으로 JDBC 사용 : 개발자가 직접 JDBC를 구현하면 개발의 효율성이 떨어지는 것을 보완하여 개발자 대신 적절한 SQL을 생성하고 데이터베이스를 조작하여 객체를 자동 매핑하는 역할을 수행

JPA 기반 구현체 중 가장 많이 사용되는 것이 하이버 네이트
4. 하이버네이트
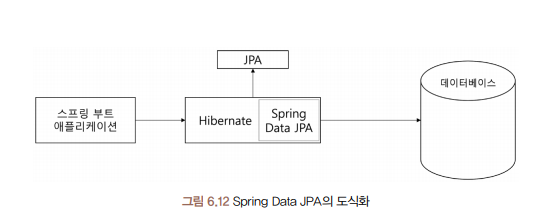
4.1 Spring Data JPA
Spring Data JPA : JPA를 편리하게 사용할 수 있도록 지원하는 스프링 하위 프로젝트 중 하나
CRUD 처리에 필요한 인터페이스를 제공
하이버네이트의 엔티티 매니저(entity manager)를 직접 다루지 않고 레포지토리를 정의해 사용함
-> 적합한 쿼리를 동적으로 생성하는 방식으로 데이터베이스를 조작
5. 영속성 컨텍스트
영속석 컨텍스트(Persistance Context) : 애플리케이션과 데이터베이스 사이에서 엔티티와 레코드의 괴리를 해소하는 기능 + 객체를 보관하는 기능
엔티티 객체가 영속성 컨텍스트에 들어와 JPA의 관리 대상이 되는 시점부터는 해당 객체를 영속 객체(Persistanxe Object)라고 함

영속성 컨텍스트는 세션 단위의 생명주기를 가짐.
데이터베이스에 접근하기 위한 세션이 생성되면 영속성 컨텍스트가 만들어지고, 세션이 종료되면 영속성 컨텍스트도 없어짐
엔티티 매니저는 이러한 일련의 과정에서 영속성 컨텍스트에 접근하기 위한 수단으로 사용
5.1 엔티티 매니저
엔티티 매니저(Entity Manager) : 엔티티를 관리하는 객체, EntityManagerFactory를 통해 생성되며 데이터 베이스에 접근해서 CRUD 작업을 수행
• find() 메서드
Primary Key를 사용하여 Entity 객체를 조회하는데, 우선 1차적으로 영속성 컨텍스트를 조회하고,
영속성 컨텍스트의 1차 캐시에 해당 엔티티 정보가 존재하지 않는 경우, 데이터베이스를 통해 해당 엔티티를 조회한다.
데이터베이스에 해당 데이터 정보가 존재하는 경우, 데이터베이스로부터 반환된 정보를 통해 엔티티를 생성하여 영속성
컨텍스트의 1차 캐시에 저장하고, 영속성 컨텍스트에 저장된 데이터를 반환하여 준다
• persist() 메서드
새로운 Entity 객체를 영속성 컨텍스트에 등록하는 것으로 이 이후부터 해당 엔티티는 EntityManager에 의해 관리된다. 그래서 해당 Entity에 변경이 발생하는 경우 EntityManager는 이를 데이터베이스에 반영한다. EntityManager는 그러한 변화에 대한 처리를 데이터베이스에 바로 바로 하지 않고 내부 쿼리 저장소에 관련 sql을 모아두었다가 커밋이 있을 때, 최종적으로 한 번에 해당 쿼리들을 데이터베이스에 전달함으로써 성능을 최적화 한다. 트랜잭션을 커밋하면 영속성 컨텍스트의 데이터를 데이터베이스에 반영하는 플러시가 발생하여, 영속성 컨텍스트와 데이터베이스 간 동기화가 이루어진다.
• remove() 메서드
영속성 컨텍스트에서 Entity 객체를 삭제한다.
• merge() 메서드
Entity 객체의 상태를 변경하고, 변경된 상태를 데이터베이스에 반영 및 새로운 영속 상태의 엔티티를 반환한다.
• flush() 메서드
영속성 컨텍스트의 변경 내용을 데이터베이스에 반영한다. 플러시는 flush()메서드의 직접 호출, 커밋, jpql 쿼리 실행 시의 경우에 발생한다.
• refresh() 메서드
데이터베이스에서 Entity 객체를 다시 조회하여 영속성 컨텍스트의 상태를 업데이트한다.
Spring Data JPA를 사용하면 리포지토리를 사용해서 데이터베이스에 접근하는데, 이때 실제 내부 구현체인 SimpleJpaRepository는 다음과 같다.
public SimpleJpaRepository(JpanEntityInformation<T,?> entityInformation, EntityManager entityManager) {
Assert.notNull (entityInformation, "JpanEntityInformation must not be null!");
Assert.notNull (entityManager, "EntityManager must not be null!");
this.entityInformation = entityInformation;
this.em = entityManager;
this.provider = PersistenceProvider.fromEntityManager(entityManager);
}이렇게 엔티티 매니저가 사용됨을 알 수 있고 엔티티 매니저는 엔티티 매니저 팩토리(EntityManagerFactory)가 만듬
엔티티 매니저 팩토리 (Entity Manager Factory): ManagerFactory는 EntityManager를 생성 관리하고, 데이터베이스와의 연결을 설정하는 역할을 하며, Entity 클래스와 매핑 정보를 읽어온다.
애플리케이션의 시작 시점에서 한 번만 생성되어 애플리케이션 전역에서 공유되어 사용된다. EntityManagerFactory는 데이터베이스에 대응하는 객체로서 스프링 부트에서는 자동 설정 기능이 있기 떄문에 application.properties에서 작성한 최소한의 설정만으로도 동작하지만 JPA의 구현체 중 하나인 하이버네이트에서는 persistence.xml이라는 설정 파일을 구성하고 사용해야하는 객체이다. Persistence 클래스의 createEntityManagerFactory() 메서드를 통해 생성할 수 있는데, 이때 인자에는 persistence.xml에 설정해준 persistence-unit 명을 넣어준다.
* persistence.xml은 jpa를 사용하기 위한 설정 파일로, EntityManagerFactory 생성시 관련 설정에 대한 내용을 읽어오는 파일이라 할 수 있다. resources의 하위에 META-INF폴더에 persistence.xml 파일명으로 생성하면 되며, 해당 파일을 통해 데이터베이스 드라이버 클래스, JDBC URL, user, password, 데이터베이스에 연동될 클래스 파일 위치 등의 정보를 설정할 수 있다.
5.2 엔티티의 생명주기
- 비영속(New) : 영속성 컨텍스트에 추가되지 않은 상태
- 영속(Managed) : 영속성 컨텍스트에 의해 엔티티 객체가 관리되는 상태
- 준영속(Detached) : 영속성 컨텍스트에 의해 관리되던 엔티티 객체가 컨텍스트와 분리된 상태
- 삭제(Removed) : 데이터베이스에서 레코드를 삭제하기 위해 영속성 컨텍스트에 삭제 요청을 한 상태
6.데이터베이스 연동
6.1 프로젝트 생성
jpa라는 프로젝트를 다음과 같은 라이브러리를 선택하여 생성한다.
Developer Tools: Lombok, Spring Configuration Processor
Web: Spring Web
SQL: Spring Data JPA, MySQL Driver
생성한 프로젝트에서 Swagger 의존성과 애플리케이션이 정상적으로 실행될 수 있게 연동할 데이터베이스의 정보를 application.properties에 작성한다.



7. 엔티티 설계
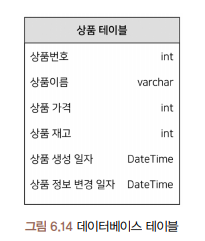
Spring Data JPA를 사용하면 데이터베이스에 테이블을 생성하기 위해 직접 쿼리를 작성할 필요가 없이 해당 기능을 가능하게 하는것이 엔티티
JPA에서 엔티티 : 데이터베이스의 테이블에 대응하는 클래스
엔티티에는 데이터베이스에 쓰일 테이블과 칼럼을 정의. 엔티티에 어노테이션을 사용하면 테이블 간의 연관관계 정의 가능
7.1 엔티티 관련 기본 어노테이션
@Entity : 해당 클래스가 엔티티임을 명시하기 위한 어노테이션
@Table : 클래스의 이름과 테이블의 이름을 다르게 지정해야 하는 경우
@Id : 테이블의 기본값, 모든 엔티티는 @Id 어노테이션이 필요
@GeneratedValue : 해당 필드의 값을 어떤 방식으로 자동으로 생성할 지 결정할 때 사용
- GeneratedValu를 사용하지 않는 방식(직접 할당)
- AUTO
- IENTITY
- SEQUENCE
- TABLE
@Colulmn : 필드에 몇 가지 설정을 더할 때 사용
- name
- nullable
- length
- unique
@Transient : 엔티티 클래스에는 선언돼 있는 필드지만 데이터베이스에서는 필요 없을 경우
8.리포지토리 인터페이스 설계
Spring Data JPA는 JpaRepository를 기반으로 더 쉽게 데이터베이스를 사용할 수 있는 아키텍쳐를 제공한다.
8.1 리포지토리 인터페이스 생성
리포지토리(Repository) : Spring Data JPA가 제공하는 인터페이스, 엔티티가 생성한 데이터베이스에 접근하는 데 사용
public interface ProductRepository extends JpaRepository<Product, Long> {
}ProductRepository가 JpaRepository를 상속받을 때는 대상 엔티티와 기본값 타입을 지정
@NoRepositoryBean
public interface JpaRepository<T, ID› extends PagingAndSortingRepository<T, ID›,QueryByExampleExecutor<T) {
List<T findAl1();
List<T) findAl1(Sort sort);
List<T) findAllById(Iterable<ID) ids);
(S extends T List<S) saveAll(Iterable<S› entities);
void flush;
(S extends T) S saveAndFlush(S entity);
(S extends T) List(S) saveAllAndFlush(Iterable<S) entities);
@Deprecated
default void deleteInBatch(Iterable<T) entities) {
this.deleteAllinBatch(entities);
}
void deletellinBatch(Iterable<T) entities);
void deleteAllByIdInBatch(Iterable<ID) ids);
void deleteAllInBatch();
@Deprecated
T getOne (ID id);
T getByld(ID id);
<S extends T) List(S) findAll (Example<S) example);
<S extends T> List(S) findAll (Example<S) example, Sort sort);
}JpaRepository의 상속 구조

8.2 리포지토리 메서드의 생성 규칙
- FindBy: SQL문의 where 절 역할을 수행하는 구문입니다. findBy 뒤에 엔티티의 필드값을 입력해서 사용합니다.
- 예) findByName(String name)
- AND, OR: 조건을 여러 개 설정하기 위해 사용합니다.
- 예) findByNameAndEmail(String name, String email)
- Like/NotLike: SQL문의 like와 동일한 기능을 수행하며, 특정 문자를 포함하는지 여부를 조건으로 추가합니다. 비슷한 키워드로 Containing, Contains, isContaing이 있습니다.
- StartsWith/StartingWith: 특정 키워드로 시작하는 문자열 조건을 설정합니다.
- EndsWith/EndingWith: 특정 키워드로 끝나는 문자열 조건을 설정합니다.
- IsNull/IsNotNull: 레코드 값이 Null이거나 Null이 아닌 값을 검색합니다.
- True/False: Boolean 타입의 레코드를 검색할 때 사용합니다.
- Before/After: 시간을 기준으로 값을 검색합니다.
- LessThan/GreaterThan: 특정 값(숫자)을 기준으로 대소 비교를 할 때 사용합니다.
- Between: 두 값(숫자) 사이의 데이터를 조회합니다.
- OrderBy: SQL 문에서 order by와 동일한 기능을 수행합니다. 예를 들어, 가격순으로 이름 조회를 수행한다면 List<Product> findByNameOrderByPriceAsc(String name);와 같이 작성합니다.
- countBy: SQL 문의 count와 동일한 기능을 수행하며, 결괏값의 개수(count)를 추출합니다.
9. DAO 설계
DAO(Data Access Object) : 데이터베이스에 접근하기 위한 로직을 관리하기 위한 객체
비즈니스 로직의 동작 과정에서 데이터를 조작하는 기능은 DAO 객체가 수행하지만 JPA에서 DAO의 개념은 리포지토리가 대체
DAO vs. 리포지토리
DAO와 리포지토리는 역할이 비슷하여 아직도 DAO와 리포지토리를 비교하거나 어떤 차이가 있는지 논쟁하는 경우가 많다.
실제로 리포지토리는 Spring Data JPA에서 제공하는 기능이기 때문에 기존의 스프링 프레임워크나 스프링 MVC의 사용자는 리포지토리라는 개념을 사용하지 않고 DAO 객체로 데이터베이스에 접근
9.1 DAO 클래스 생성
DAO 클래스
: 일반적으로 '인터페이스-구현체' 구성으로 생성
- 의존성 결합을 낮추기 위한 디자인패턴, 서비스 레이어에 DAO 객체를 주입받을 때 인터페이스를 선언하는 방식
인터페이스
- 데이터베이스에 접근하는 메서드는 리턴 값으로 데이터 객체를 전달
- 이때 엔티티 객체로 전달할지, DTO 객체로 전달할지에 대해서는 개발자마다 다름
'공log > [SpringBoot]' 카테고리의 다른 글
| [SpringBoot] #5 API를 작성하는 다양한 방법 (0) | 2023.09.03 |
|---|---|
| [Spring Boot] #4 스프링 부트 애플리케이션 개발하기 (0) | 2023.09.02 |
| [Spring Boot] #3 개발 환경 구성 (0) | 2023.08.27 |
| [SpringBoot] #2 개발에 앞서 알면 좋은 기초 지식 (0) | 2023.08.27 |
| [Spring Boot] #1 스프링 부트란? (0) | 2023.08.26 |